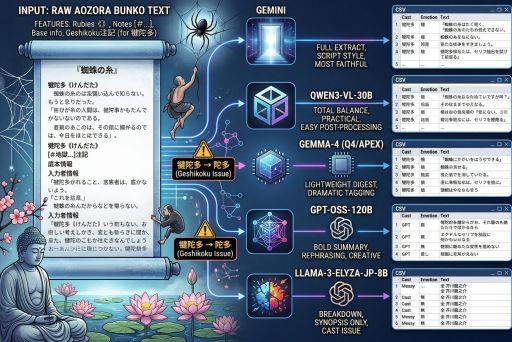
『蜘蛛の糸』でセリフ抽出と感情分類を比較してみた
青空文庫の生テキストをそのまま入力し、各LLMに「キャスト・感情・文章」のCSV形式で 音声台本を抽出させたベンチマークです。今回は、原文保持性・感情付与・フォーマット安定性・実運用のしやすさを中心に比較しました。
ベンチマーク条件
今回の比較では、前処理なしの青空文庫テキストをそのまま使用しました。 つまり、ルビ記法《》、|記号、入力者注[#…]、底本情報まで含めた状態で各モデルに同じ指示を与えています。
先に結論
もっとも忠実
Gemini全文網羅性が高く、朗読台本としてもっとも素直な出力でした。
総合バランス最強
Qwen3-VL-30B長さ・情報量・後処理のしやすさのバランスが非常に良好でした。
軽量運用向き
Gemma Q4_K_M要約寄りですが、軽く使いたい場合には扱いやすい出力です。
今回の用途では厳しい
gpt-oss / ELYZA再表現寄り、またはキャスト崩壊があり、厳密な抽出用途には向きませんでした。
モデル別の印象
Gemini
全文網羅 指示忠実冒頭から結末までかなり丁寧に追い、感情推移も自然でした。 今回の比較では、もっとも「ちゃんと全部やる」タイプです。
Qwen3-VL-30B
総合バランス 実運用向き長すぎず短すぎず、重要場面をしっかり拾うバランス型。 後処理のしやすさまで含めると、実運用ではかなり強い印象でした。
Gemma APEX Mini
演出寄り 感情細かめQ4版よりも細かく、感情付与が積極的です。 その分、やや「盛る」傾向があり、厳密抽出よりドラマ寄りでした。
Gemma Q4_K_M
軽量 要約寄り見やすく軽い反面、かなりダイジェスト寄り。 朗読台本としては情報量が少なめでした。
gpt-oss-120b
再表現寄り フォーマット崩れ原文抽出というより、自分の言葉で言い換える傾向が強めでした。 キャスト欄崩れもあり、今回の用途では厳しめです。
Llama-3-ELYZA-JP-8B
超ダイジェスト キャスト崩壊すべてのキャストが「芥川龍之介」になるなど、用途不一致がはっきり出ました。 あらすじ化はできるものの、台本用CSVには不向きです。
比較表
| モデル | 傾向 | 強み | 弱み |
|---|---|---|---|
| Gemini | 全文網羅・朗読台本型 | 原文保持、感情推移、フォーマット安定 | 出力が長め |
| Qwen3-VL-30B | 総合バランス型 | 長さと情報量のバランス、実用性 | Geminiほどの網羅性はない |
| Gemma APEX Mini | 演出寄り抽出型 | 感情付与が細かい | やや感情を盛る |
| Gemma Q4_K_M | 軽量ダイジェスト型 | 見やすく軽い | 要約寄りで原文忠実性が弱い |
| gpt-oss-120b | 再構成・言い換え型 | 文章としては読みやすい | 抽出用途では崩れやすい |
| ELYZA 8B | 超ダイジェスト型 | 短く軽い | キャスト崩壊、用途不一致 |
今回わかったこと
- 同じ指示でも、モデルごとに「抽出」と解釈するか「要約」と解釈するかが違う。
- Gemini はもっとも忠実、Qwen3-VL-30B はもっとも実用的だった。
- Gemma系は軽量または演出寄りとして面白いが、用途によって向き不向きが分かれる。
- gpt-oss と ELYZA は物語理解はしていても、今回のCSV抽出用途とはズレが大きかった。
- 青空文庫の外字注記はどのモデルでも課題で、前処理の重要性が非常に高い。
まとめ
今回の比較で見えたのは、単純なモデル性能の差だけではありません。 同じプロンプトに対して、各モデルが「これは原文抽出なのか」「要点整理なのか」「分かりやすい再表現なのか」を違う形で解釈していた点が非常に興味深いところでした。
オーディオブックや朗読台本を本気で作るなら、モデル選びだけでなく、 注記除去・ルビ処理・本文保護といった前処理を含めてワークフロー全体で設計する必要があります。

コメント